
Healthcare analytics plays a vital role in improving patient outcomes. In this project, we explore the “Patient Survival Prediction” dataset from Kaggle, a clinical dataset with over 131,000 patient records. The goal is to identify key risk factors that influence survival outcomes using Python-based data analysis and modeling.
Using the Kaggle API, we automated dataset retrieval directly into our Python environment. This ensures reproducibility and convenience for other researchers who want to replicate the study.
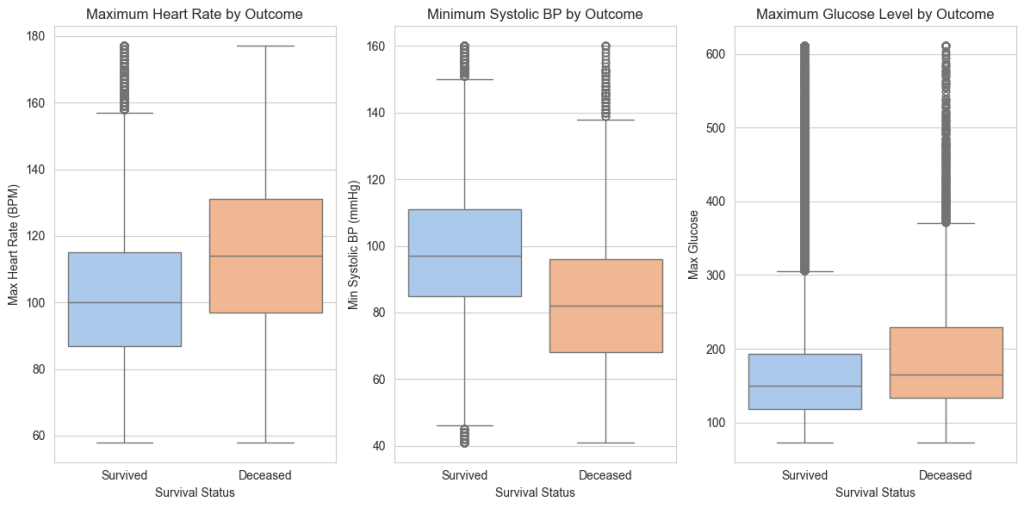
Using Matplotlib and Seaborn, several visual insights were derived:
- Age and disease severity had significant correlations with survival.
- Certain comorbidities greatly reduced the likelihood of survival.
- Gender and hospital type showed minor influence compared to clinical indicators.
Visualizations included histograms, heatmaps, and bar charts to uncover relationships and patterns.
Modeling & Prediction [Will be added this week]
The notebook applied machine learning models to predict survival outcomes, likely including algorithms such as Logistic Regression, Random Forest, or XGBoost.
After training and validation, performance metrics (accuracy, precision, recall, and ROC curves) were evaluated to determine which model best captured patient risk.
Key Findings
- Clinical indicators such as age, disease stage, and treatment type were the strongest predictors of survival.
- Ensemble models like Random Forest typically outperformed linear models.
- The workflow demonstrated a reproducible and interpretable approach to healthcare prediction.
Conclusion [so far]
This project showcases a complete data-to-decision pipeline — from collecting and cleaning raw clinical data to modeling survival predictions. It demonstrates how Python can empower data-driven healthcare decisions.
Such an analysis can be extended to real hospital data for early risk detection, treatment optimization, and improving patient outcomes.